데이터를 얻는 방법과 웹크롤링 기본 구조
데이터 분석 프로젝트를 하면서 난감했던 것 중 하나가 하고자 하는 프로젝트 주제에 맞는 데이터가 없을 때였다. 우연하게 활동했던 동아리에서 크롤링 관해서 강연을 하게되었는데 크롤링 말고도 데이터를 받을 수 있는 방법들에 대해 소개해주고 싶었고 크롤링에 대한 기본 구조를 다시 살펴보고 실습을 진행하였다.
발표를 해도 아쉬움이 항상 남는데 그것을 채우고 나도 다시 정리해보고 싶어 글을 쓰게 되었다.
내용 중 생략한 내용이나 부족한 부분은 밑에 제가 참고한 영상과 자료들을 첨부하니 그 밑의 부분을 찾아보시면 더 자세하게 공부하실 수 있습니다.
크롤링말고 데이터를 얻는 방법이 없을까??
1) 공개된 데이터셋
국내나 해외의 공개된 데이터셋을 정리해놓거나 개방해놓은 사이트들이 많다. 대표적인 사이트들이 많은 데 대표적인 사이트들을 정리해 봤습니다.
kaggle은 여러 기업에서 dataset을 주어지며 예측 모델링 및 분석 대회 플랫폼입니다.
끝난 대회더라도 datasets에 들어가게되면 검색할 수 있습니다.
kaggle에 대해서 더 알고 싶으시다면 변성윤님의 github을 참고해주세요!
검색을 통해서 dataset을 찾고 싶담녀 Google이 만든 데이터셋을 찾아주는 engine을 이용해봅니다!

기본 배공화면은 구글과 유사합니다!
기본적으로 영어로 제공되면서 한글도 됩니다!
국내 데이터에 대해서 볼 때 주로 공공데이터포털을 이용하는데
공공데이터포털뿐만 아니라 다른 국내 공공데이터들의 리스트들을 모아두고 국내에서 가장 큰 검색 포털의 인사이트를 볼 수 있는 여러 탭이 있어 이곳을 소개해드립니다.
2) API(Application Programming Interface)
응용 프로그램에서 사용할 수 있도록, 운영 체제나 프로그래밍 언어가 제공하는 기능을 제어할 수 있게 만든 인터페이스
쉽게 말하면, API 제공하는 곳에서 자신이 가진 데이터베이스 or 기능을 사용자가 쉽게 사용하게 할 수 있도록 제공하는 모듈이라고 생각하면 좋을 것 같습니다.
크롤링 하기전 각 사이트에서 제공하는 API를 통해서 쉽게 데이터를 접근 할 수 있습니다. 밑의 예시로 둔 사이트말고도 해외 기업은 api를 제공하는 경우가 있으니 찾아보시면 좋을 것 같습니다!
API 사용법은 밑의 오픈 api사이트들을 찾아보시면 됩니다!
오픈 api 사이트
크롤링 기본 구조
데이터셋도 찾아보고 api도 제공이 안된다고 판단되면 크롤링을 시작해봅시다!
저는 Python을 이용해서 크롤링을 진행했습니다.
다른 언어를 통해서도 크롤링은 가능합니다.
크롤링에서 자주 사용하는 라이브러리
Requests : 파이썬에서 동작하는 작고 빠른 브라우저
- get방식으로 소스를 가져옵니다
BeutifulSoup4: Html 파서
- 지정 html로 부터 원하는 위치/형식의 문자열을 획득
Selenium : 브라우저를 원격 컨트롤 하는 테스팅 라이브러리
- Chrome,FireFox, Phantom JS등에서 이용가능
- 동적인 사이트들이나 추가적인 액션( 로그인, 버튼)이 필요할 때 이용
크롤링의 순서
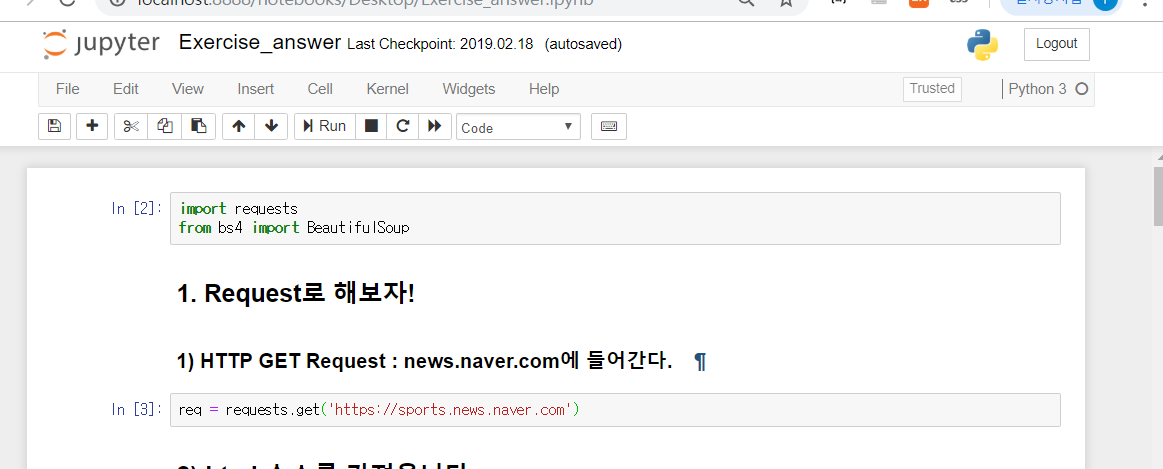
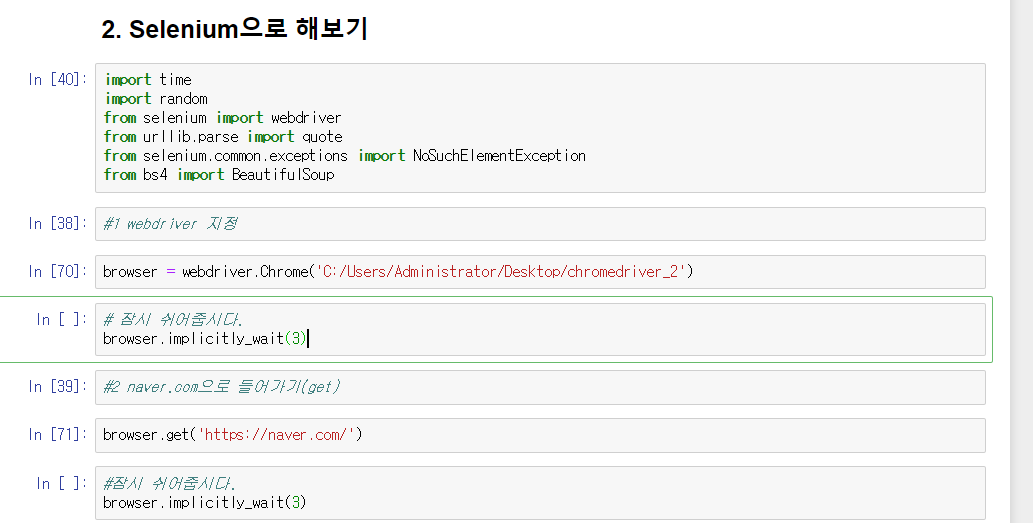
1) Requests/Selenium 라이브러리를 통해 크롤링을 원하는 사이트에 get요청을 한 후
- Requests
- Selenium
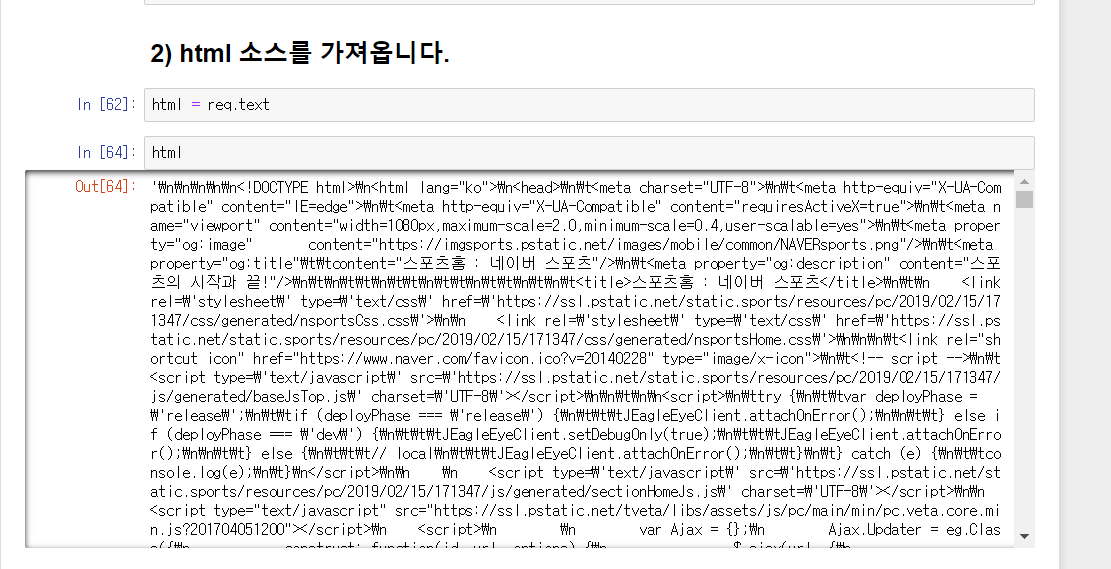
2) Html 소스를 받아 오고
3) Html 파서을 이용하해 파이썬이 이해할 수 있게 해주고
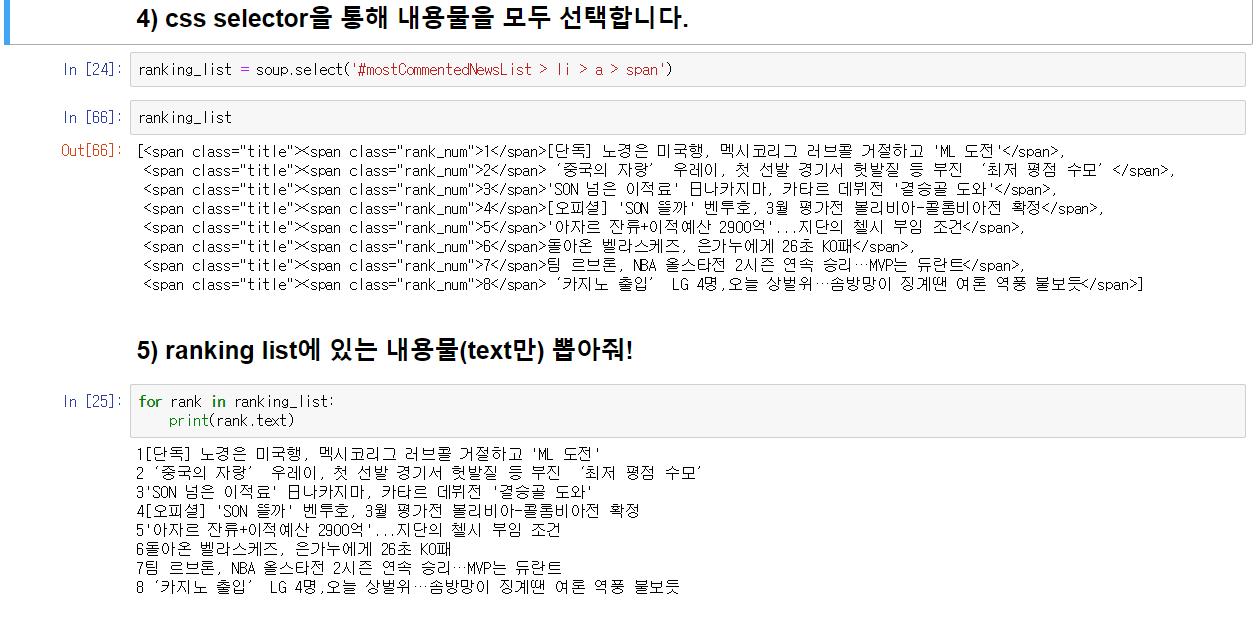
4) 필요한 부분을 여러 함수 (CSS selector, find)등을 이용해 찾
아낸다.
참고하고 공부한 사이트(+크롤링 공부하시면서 보시면 좋은 자료)
