pandas with data1
Pandas with data 1
저번 글에서는 pandas라이브러리에서 많이 쓰이는 method을 정리했습니다.
이번 글에서는 pandas가 실제 분석에서 어떻게 쓰이는지 알아보기위해 titanic데이터를 통해 알아보겠습니다!
이번 글에서는 데이터를 불러오고 확인하는 법, 결측치 처리, grouping, apply(함수) 적용에 대해 알아보겠습니다!
우선, 필요한 라이브러리들을 불러옵니다.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
plt.style.use('seaborn')
sns.set(font_scale=2.5)
import missingno as msno
#ignore warnings
import warningsimport numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
plt.style.use('seaborn')
sns.set(font_scale=2.5)
import missingno as msno
#ignore warnings
import warnings
warnings.filterwarnings('ignore')
# notebook에서 바로 볼 수 있게!
%matplotlib inline
warnings.filterwarnings('ignore')
1. 데이터 불러오기&데이터 확인하기
1) pd.read_csv을 통해 데이터를 불러옵니다.
df_train = pd.read_csv('../train.csv',index_col='PassengerId')
df_test = pd.read_csv('../test.csv',index_col='PassengerId')
혹시 index 컬럼이 있는 경우 위에 처럼 지정해 줄 수 있습니다.
2) 데이터 형태 보기
df_train.head()
output :
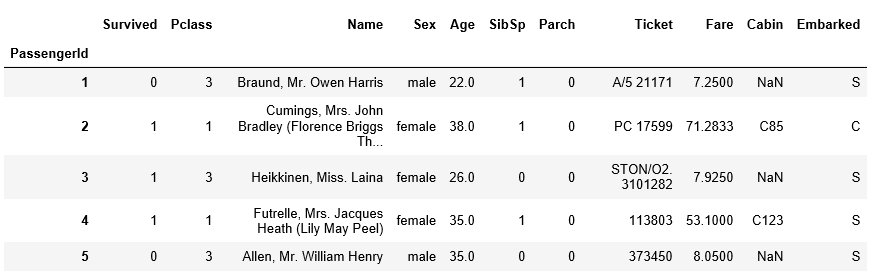
데이터프레임.head()는 데이터 프레임의 앞 다섯행을 보여줍니다.
()안에 숫자를 넣으면 그 수만큼 보여줍니다.
.tail()은 데이터프레임의 뒷 행을 보여줍니다.
3) Column 재배열
현재 dataframe을 보면 target column인 Survived Column이 맨 앞에 놓여있습니다. 분석의 용이성을 위해 Survived을 맨뒤 column에 재배열 해보겠습니다.
#DataFrame의 column을 확인합니다.
df_train.columns
#원하는 column의 순서대로 배열을 해줍니다.
df_test = df_test[['Pclass', 'Name', 'Sex', 'Age', 'SibSp', 'Parch', 'Ticket','Fare', 'Cabin', 'Embarked']]
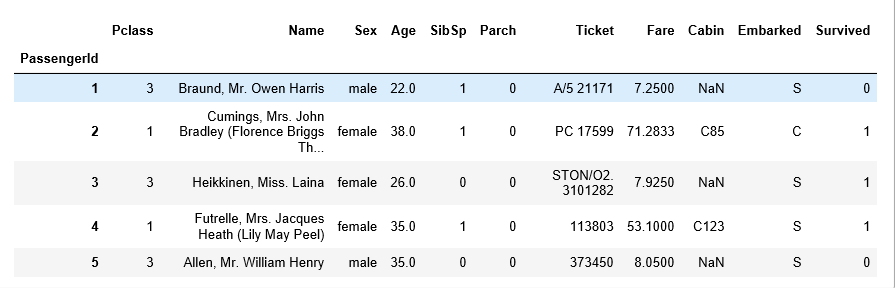
4) column들의 데이터 타입 및 기초 통계량
몇가지 함수들을 통해 데이터타입과 기초 통계량을 확인 할 수 있습니다.
df_train.dtypes

위와 같이 데이터 타입을 확인 할 수 있다.
df_train.describe()
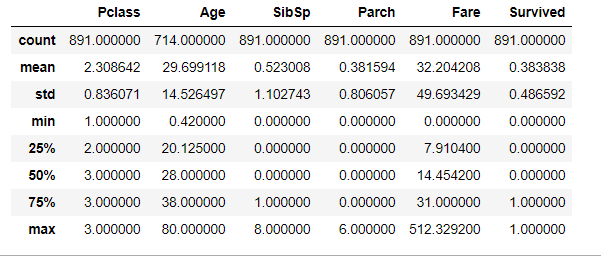
describe() 매소드를 통해 칼럼이 int형이나 float형인 경우 간단한 통계정보를 보여줍니다!
df_train.corr()
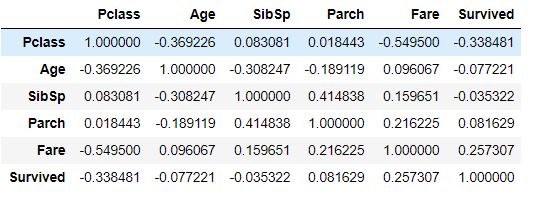
corr() method는 각 칼럼 사이의 상관계수를 보여줍니다.
5) 결측치 처리
우선 결측치를 확인합니다.
df_train.isnull().head()
위와 같이 isnull() method을 활용하면 위와 같이 각 셀 별로 null값인지 확인 할 수 있습니다.
하지만, 이는 보기에도 안좋고 어떻게 처리할 지 눈에 잡히지 않습니다.
for col in df_train.columns:
msg = 'column: {:>10}\t Percent of NaN value: {:.2f}%'.format(col, 100 * (df_train[col].isnull().sum() / df_train[col].shape[0]))
print(msg)
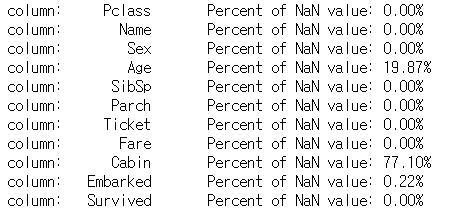
null값을 볼 때는 그 값이 비어있는지 보기 보다는 어떤 칼럼이 null 값이 많으며, 그 정도가 어느정도 되는 지가 분석 시 중요합니다. 그래서 위와 같이 비율로 확인합니다. 이에 따라 null값을 어떻게 처리할 지에도 영향을 미칩니다.
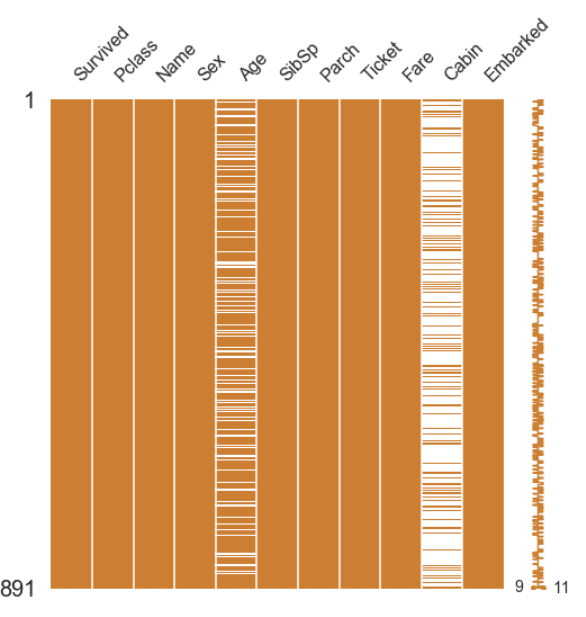
다음은 null data의 존재를 더 쉽게 볼 수missingno라는 라이브러리입니다.
msno.matrix(df=df_train.iloc[:, :], figsize=(8, 8), color=(0.8, 0.5, 0.2))
msno.bar(df=df_train.iloc[:, :], figsize=(8, 8), color=(0.8, 0.5, 0.2))
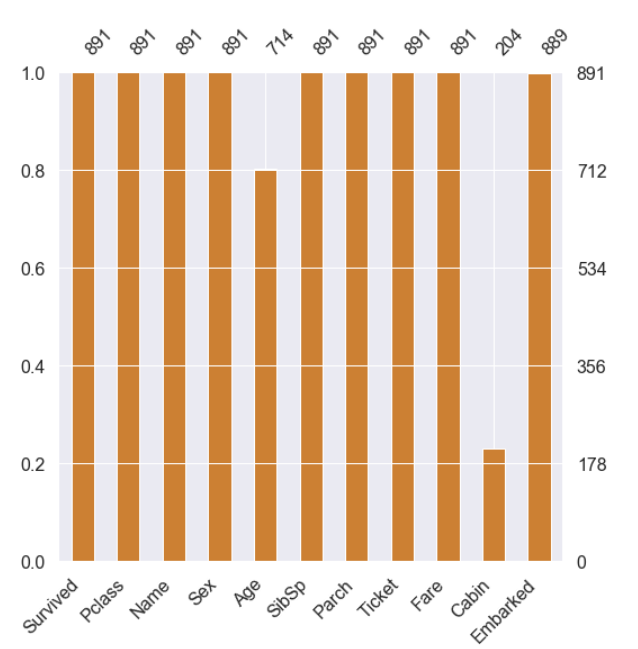
2. Grouping
다음은 EDA을 할 때 주로 쓰이는 grouping에 관련된 method들입니다.
우선, pandas을 통해 group을 지을 때는
DataFrame.groupby(‘칼럼’)
을 활용합니다.
이를 활용하여 다양한 통계량과 함수를 적용할 수 있습니다.
df_train.groupby('Sex').Survived.mean()
위를 통해 성별이라는 column의 값으로 grouping 후 해당 값의 Survived 칼럼에 대한 평균 값을 알려줍니다.

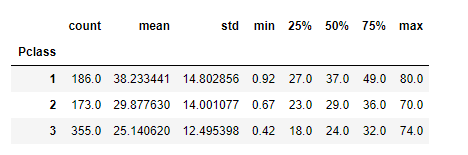
df_train.groupby('Pclass').Age.describe()
Pclass 칼럼으로 grouping 후 Age에 대한 describe 적용.
df_train.groupby(['Pclass','Sex']).agg({'Sex':'count'})
grouping을 한개의 컬럼한 한 것이 아닌 두 개 이상의 칼럼에 대해 grouping 후 함수를 적용 할 수 있습니다.

3. Apply (함수) 적용하기
기존 칼럼을 활용하여 새로운 칼럼을 생성하거나 기존 칼럼을 변경해야하는 경우, 함수를 적용하는 경우가 있습니다.
def Adult(x):
if x > 19:
return True
else:
return False
Age 칼럼을 통해 해당 사람이 성인인지에 대한 칼럼을 생성하고자 합니다.
#Age 칼럼에 함수를 적용해서 새로운 Adult라는 칼럼 생성
df_train['Adult'] = df_train['Age'].apply(Adult)
#칼럼 재조정
df_train = df_train[['Pclass', 'Name', 'Sex', 'Age', 'SibSp', 'Parch', 'Ticket', 'Fare','Cabin', 'Embarked','Adult' ,'Survived']]
df_train.head()
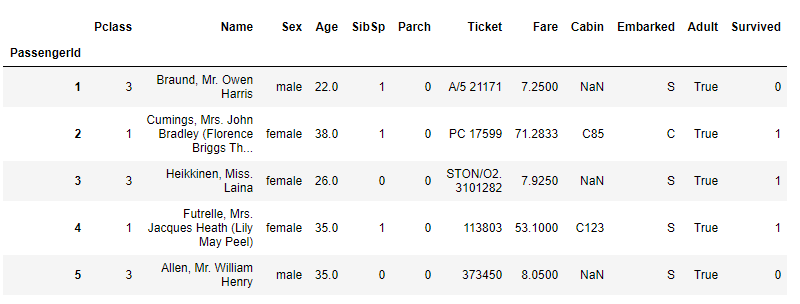
위와 같이 기존 있는 칼럼에 바로 apply함수를 적용해서 새로운 칼럼을 생성할 수 있습니다.
참고사이트
