데이터를 얻는 방법과 웹크롤링 기본 구조
데이터 분석 프로젝트를 하면서 난감했던 것 중 하나가 하고자 하는 프로젝트 주제에 맞는 데이터가 없을 때였다. 우연하게 활동했던 동아리에서 크롤링 관해서 강연을 하게되었는데 크롤링 말고도 데이터를 받을 수 있는 방법들에 대해 소개해주고 싶었고 크롤링에 대한 기본 구조를 다시 살펴보고 실습을 진행하였다.
데이터 분석 프로젝트를 하면서 난감했던 것 중 하나가 하고자 하는 프로젝트 주제에 맞는 데이터가 없을 때였다. 우연하게 활동했던 동아리에서 크롤링 관해서 강연을 하게되었는데 크롤링 말고도 데이터를 받을 수 있는 방법들에 대해 소개해주고 싶었고 크롤링에 대한 기본 구조를 다시 살펴보고 실습을 진행하였다.
in Development on WEB
페이스북 이노베이션 랩에서 진행하는 웹 프론트엔드과정을 듣고 정리한 글입니다.
동아리에서 크롤링을 공부하다보니 html, css에 간단히 배웠는데 이번에 좋은 기회를 통해 이고잉님께 배울 수 있는 기회가 생겨 수업을 듣고 필요한 내용만 정리한 내용입니다.
자세한 사항은 이고잉님의 생활코딩을 참고해주세요!
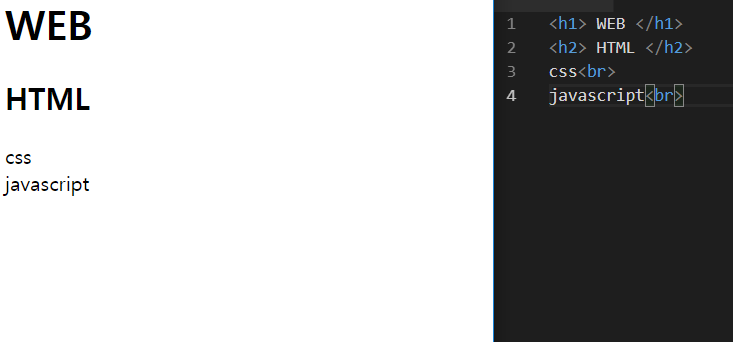
html 태그
<~>으로 시작해
</~>으로 끝난다.
u - underline
strong - 굵게
h1


br
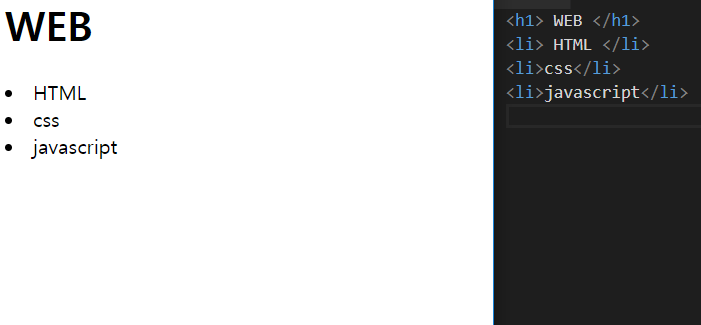
list
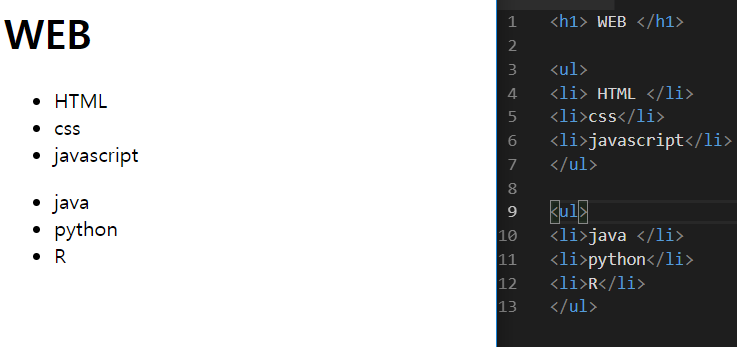
ol 태그

mark up language
팀 버너스리
WEB Browser - html
WEB Server - url
htttp
웹이 웹이기 위한 태그는?
a 태그(링크)
a 태그는 이것이 링크다 라는 것만 알려줘

title tag
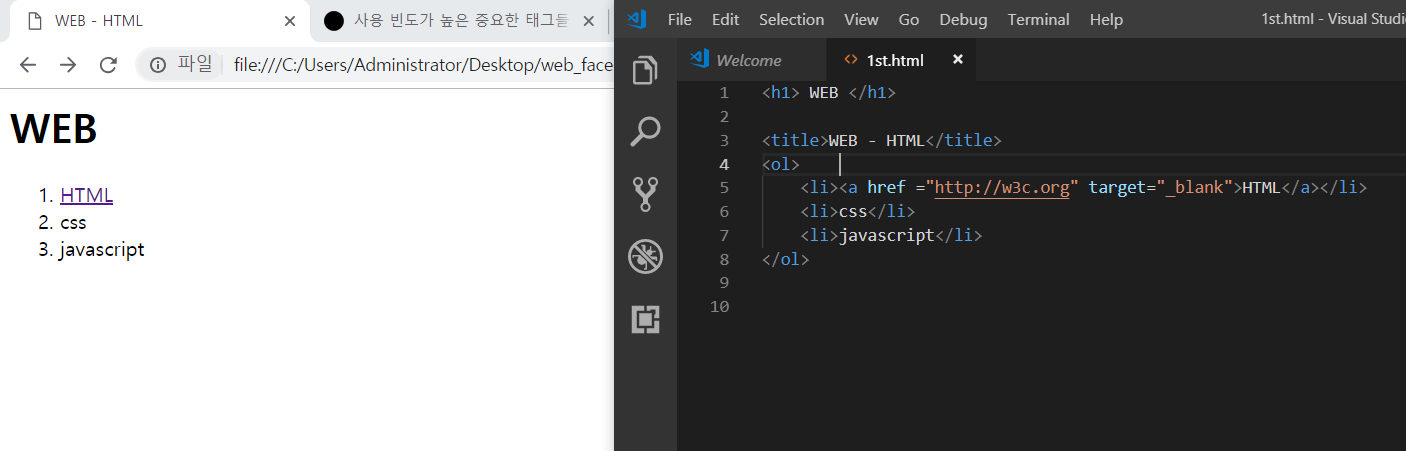
meta
데이터를 설명 하는 데이터
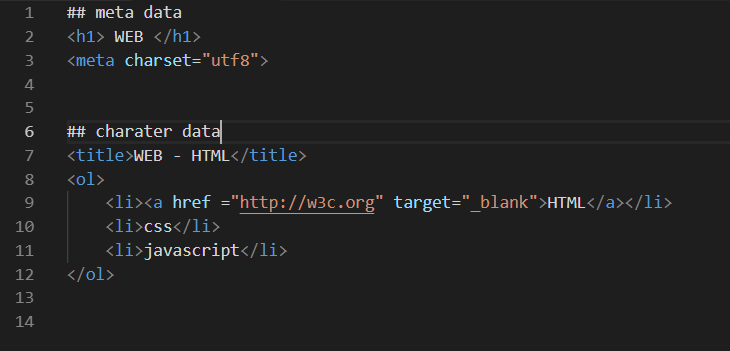
head& body
메타데이터와 컨텐츠 데이터를 나누자
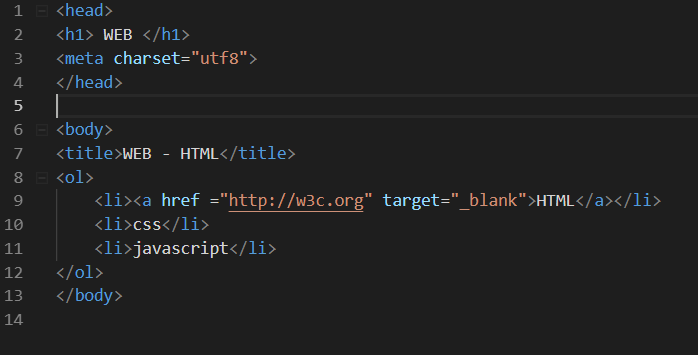
img
src에 unplash.com의 이미지를 활용해 홈페이지를 풍성하게
정보와 디자인을 분리
css 등장의 이유
css를 배운다
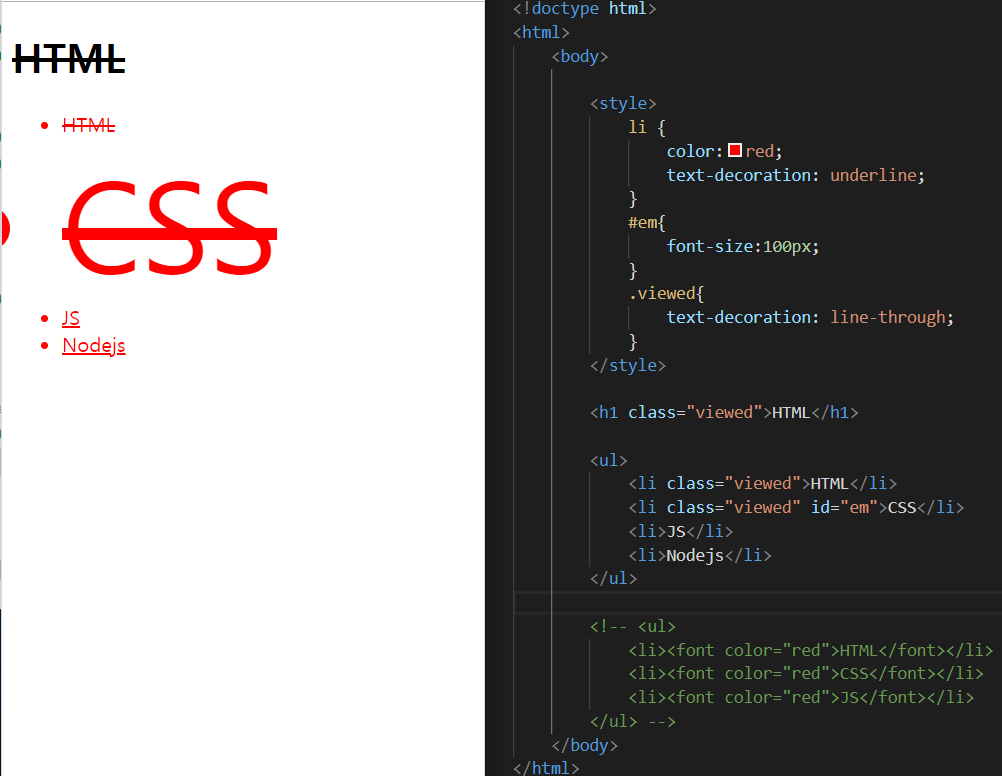
style태그로 시작 하고 끝냄
li - tag 선택자 selector
ex) li {
color : red; - 효과(description)
}
id 선택자 -단하나의 id에 해당하는 것만으로 targeting 가능
ex) #em
classs 선택자 - grouping 하는 선택자
ex) class = viewed
html 에서 말하는 elements는 태그다.
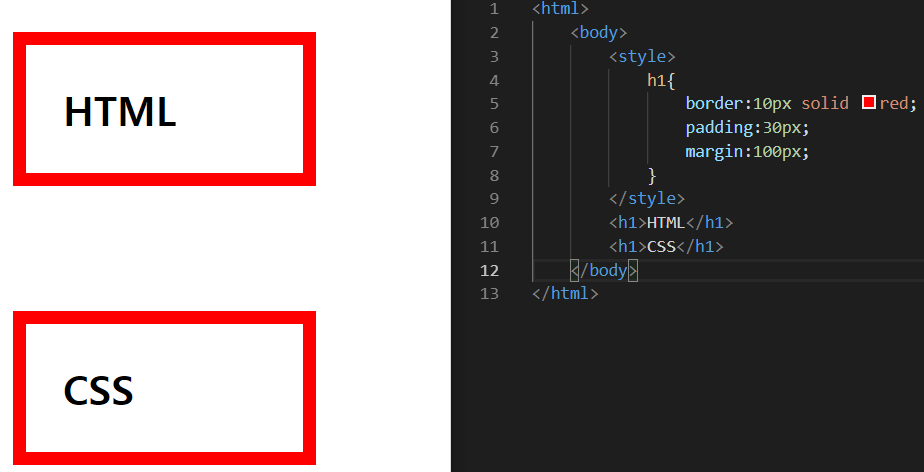
h1태그는 전체 화면을 쓴다.
border-width : 10px; - 테두리 두께
border-style : solid; - 테두리 종류
border-color : magenta; - 테두리 색깔
border : 10px solid magenta - 합쳐서 쓸 수 있다.
이고잉님이 코딩에 대해 몇가지 말씀해주신 것
알고 있는 것도 낯설게 하는 것도 능력이다.
코드는 설계도다!
하지만 건축과 다르게 설계도를 짜면 바로 프로덕트로 나온다.
결국, 오픈소스는 제품을 주는 것!
코드한줄 써보고 확인해보고
한자써보고 확인해보자 문제의 원인을 하나씩 풀어가자
코딩을 공부할 때, 중복을 제거하는 코딩을 해보자
Convolutional Neural Networks 
구조
Fully connected Neural Network(FCNN)와 비교
사진데이터를 FC신경망에 학습을 할 경우 3차원 사진데이터를 1차원으로 평면화 시켜야 한다
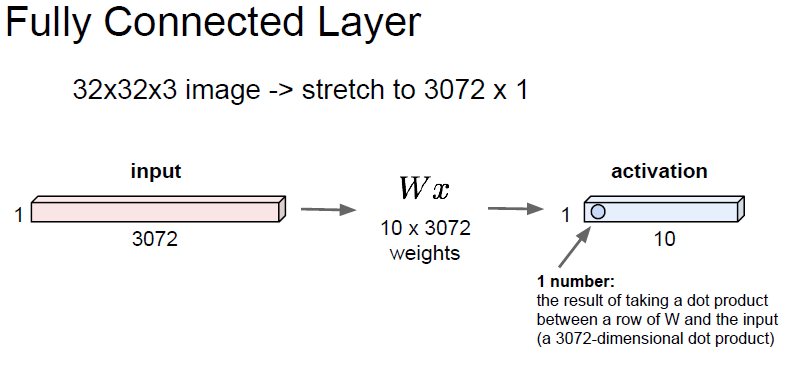
사진 데이터를 평면화 시키는 과정에서 공간 정보가 손실될 수 밖에 없다.
CNN은 이미지의 공간 정보를 유지하면서 필터,polling layer를 통해 이미지의 특징을 추출하고 학습할 수 있다는 장점을 갖고 있다.
Convolution Layer 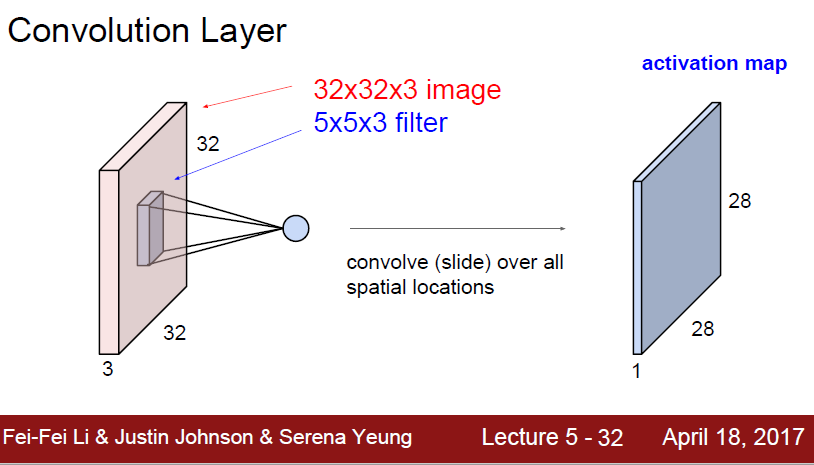
32 * 32 * 3 이미지에서 5 * 5* 3 filter 만큼의 이미지를 가져오는 것
filter의 depth는 원 이미지의 depth와 같아야한다
filter는 이미지에 차례로 돌아다니면서 이미지의 정보를 filter가 뽑아내고자하는 특성을 수집하고 그것을 모아 둔 것이 activation map
필터를 여러개 사용하면 하나당 하나의 activation map을 만든다.
filter & stride
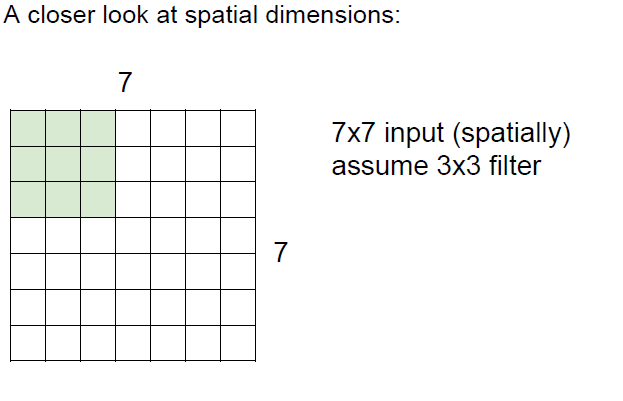
밑의 예시와 같이 7 7 input에서 3 *3 filter을 적용한다고 했을 때 *filter가 얼마나 움직일지 그 크기를 stride라고 한다.
stride가 1이라고 하면 오른쪽으로는 5번이동할 수 있고 아래로는 5번이동 할 것이다.
따라서 output은 5 * 5가 나올 것이다.
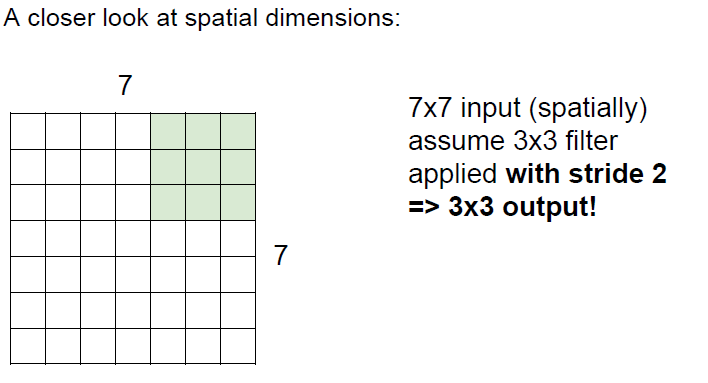
stirde가 2이라고 하면 오른쪽으로는 3번 아래로는 3번이동할수 있을것이다.
따라서 output은 3 * 3이 나올 것이다.

그래서 위와 같은 공식을 얻을 수 있게 된다
N - filter을 적용할려고 하는 이미지의 한면의 길이
F - filter의 한면의 길이
stride - filter의 stepsize

filter을 사용하다보면 output사이즈가 작아지는 경우 위와 같이 ouptut 사이즈가 줄어든다 그렇게 되면 정보의 손실이 일어나게된다.
이를 위해서 원래 이미지의 테두리에 0을 배치한다 단, 크기는 (Filter 사이즈-1)/2 크기로 만들게 된다.
F=3이라면 zero pad을 1만큼 덧붙인다.
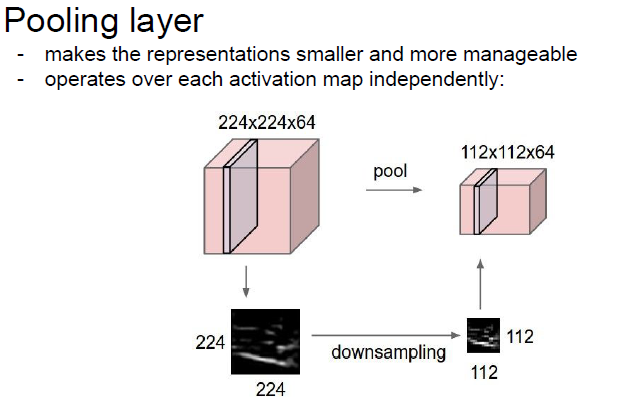
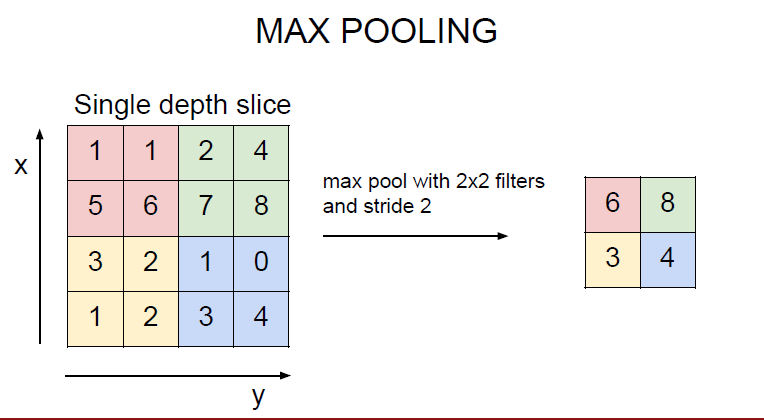
풀링레이어는 convolution layer의 activation map의 크기를 줄이거나 특정 데이터를 강조하는 용도로 사용(down sampling)
max-pooling이 대표적인 pooling 방법

https://www.youtube.com/watch?v=bNb2fEVKeEo
https://hamait.tistory.com/535
https://www.slideshare.net/leeseungeun/cnn-vgg-72164295
2018년 상반기 회고
쓰다보니 글이 길어졌고 또, 상반기와 하반기에 너무나 다른 시간을 보냈고 특히 2학기는 휴학을 하면서 진로나 고민을 하고 있는 지점이 있어서 그 점을 자세히 적고자 이번 글에서는 올해의 상반기를 정리하는 글을 적었습니다. 다음에는 하반기와 내 진로에 대해 현재 고민했던 지점과 어떻게 이어가고 있는지를 적고자합니다.
겨울방학(1월-2월)
[학업]
전역 후 고대하던 빅데이터 동아리에 들어가게 됨.
복학 준비
[개인]
3월~4월(1학기 초반)
[학업]
[개인]
5~6월(1학기 후반)
[학업]
머신러닝 알고리즘에 대한 이해, 딥러닝 기초 학습
김성훈 교수님의 모두를 위한 딥러닝/ 파이썬 라이브러리를 활용한 머신러닝 학습
동아리에서 진행하는 커리큘럼에도 겹치는 부분도 있었고 2학기 프로젝트 하기전 어느정도 학습이 필요하다고 생각해서 스터디와 학습진행
머신러닝 알고리즘들이 나에게는 처음이였고 딥러닝도 처음 듣는거라 굉장히 낯설었다.
여러가지를 찾아보고 들어보기 시작했던 시기
동아리의 대표를 맡게 되다.
[개인]
in Data on Machine-Learning
문일철 교수님의 인공지능 및 기계학습 개론 II의 8강을 듣고 정리한 것입니다.
동아리에서 프로젝트를 하면서 토픽모델링을 하고 있는데 이론적인 부분이 부족하다고 느껴 이를 잡고자 강의를 듣게 되었습니다.
위의 강의를 통해
을 정리해 보고자 합니다.
강의를 정리하면서 위와 관련된 Python code&library도 정리해보고자 합니다.
오늘 강의는
에 관해 알아 볼 것 입니다.
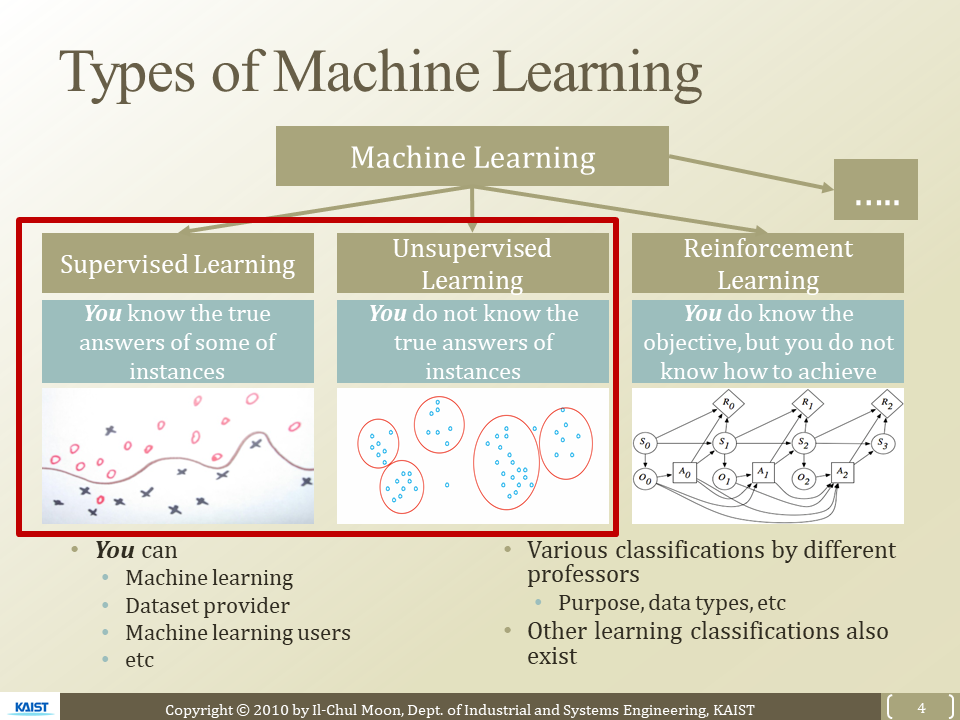
Machine Learning
Supervised Learning

Unsupervised Learning
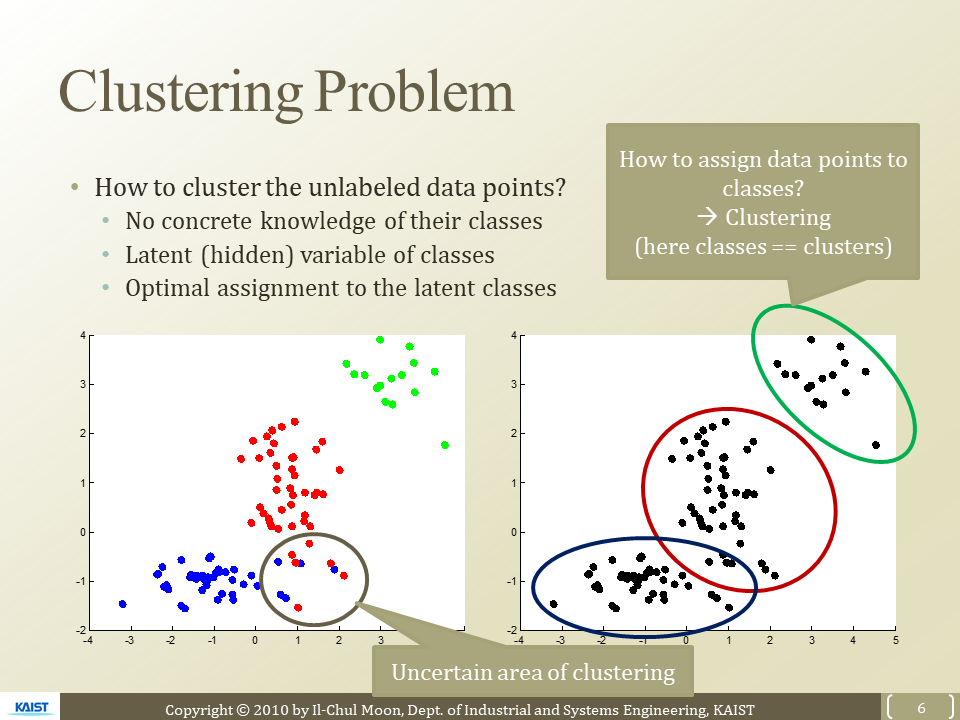
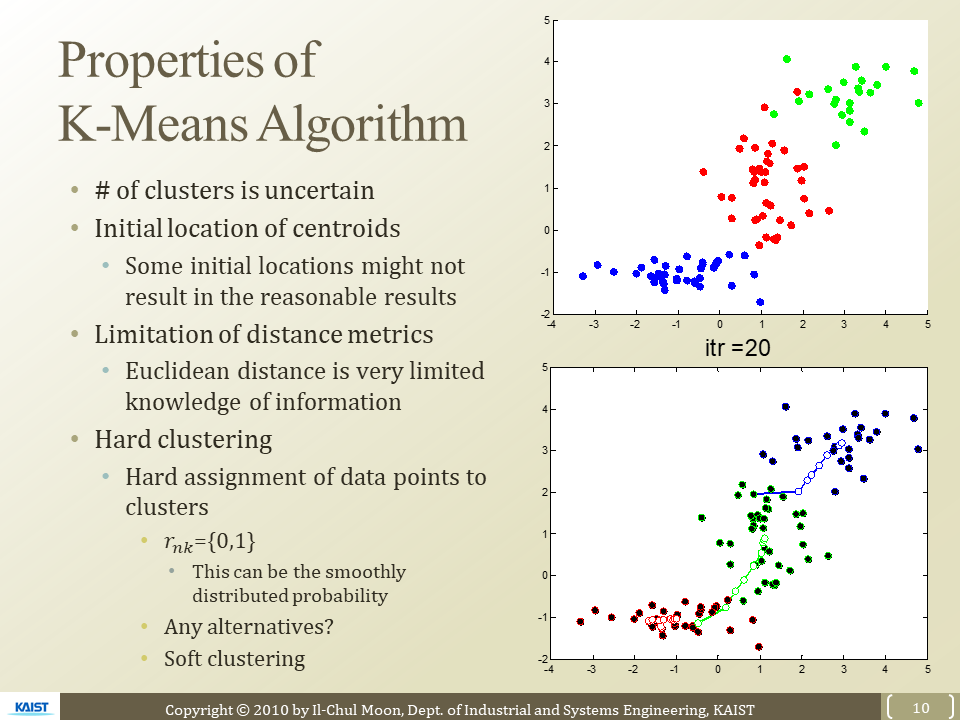
How to cluster with unlabelded data points
부정확한 클러스터링 구간이 있음 - 문제점
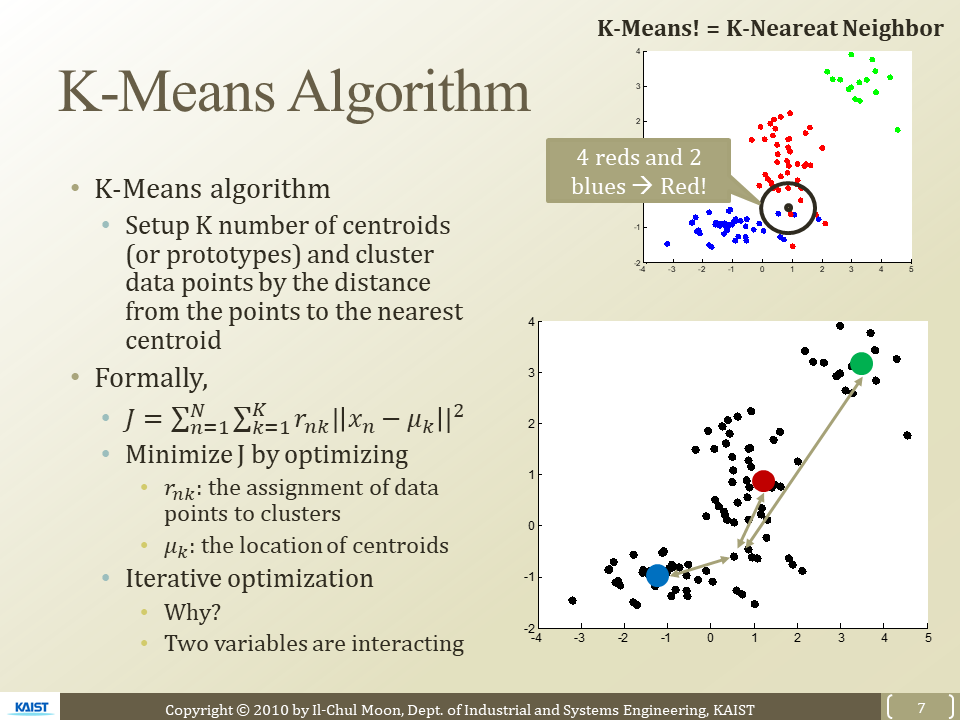
알고리즘 순서
목적함수
가장 중요한 것은 각 data points들을 거리가 가까운 Centroid 할당
= 모든 데이터 포인트들이 해당하는 Centroid와의 거리가 최소가 되게 하면 됨!
M : centroid의 위치 , X는 개별 데이터 포인트
R : assignment에 대한 정보
목적함수의 parameter는 두개(M,S)
이를 Optimize하기 위해서는 iterative Optimization해야함

Expectation - Maximization을 돌아가면서 계속 진행함