K-means Clustering
in Data on Machine-Learning
문일철 교수님의 인공지능 및 기계학습 개론 II의 8강을 듣고 정리한 것입니다.
동아리에서 프로젝트를 하면서 토픽모델링을 하고 있는데 이론적인 부분이 부족하다고 느껴 이를 잡고자 강의를 듣게 되었습니다.
위의 강의를 통해
- K-means Clustering
- Gaussian Mixture Model
- LDA with Gibbs Sampling
을 정리해 보고자 합니다.
강의를 정리하면서 위와 관련된 Python code&library도 정리해보고자 합니다.
오늘 강의는
- Unsupervised Learning
- K-means Alghorithm
- Limitation of K-means
에 관해 알아 볼 것 입니다.
Unsupervised Learning
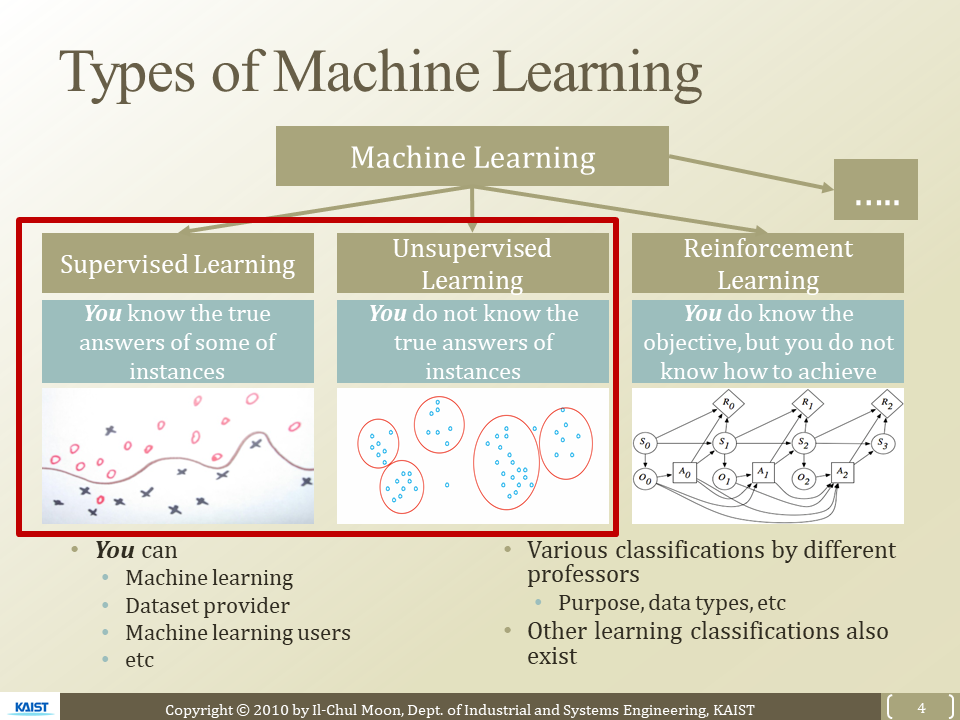
Machine Learning
- Supervised Learning
- Unsupervised Learning
- Reinforcement Learning
Supervised Learning
- True value을 아는 것
- Train case을 알고 있다
- 이를 분석해서 가정을 세우고 검정해볼 수 있다.

Unsupervised Learning
- True value값이 없다 = Tag가 없다
- Latent factors찾는 과정 = Pattern을 찾는다
- ex) Clustering, Filtering
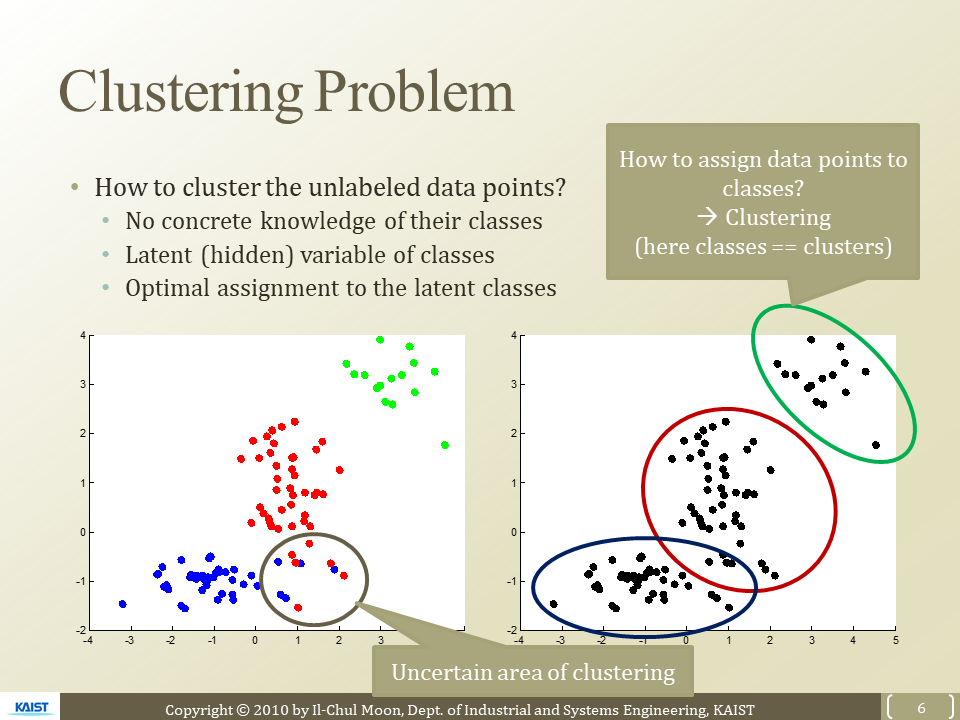
How to cluster with unlabelded data points
- 잠재적인 class(cluster) 결정
- class에 맞게 data points 할당
- 이를 Optimized
부정확한 클러스터링 구간이 있음 - 문제점
K-Means Algorithm
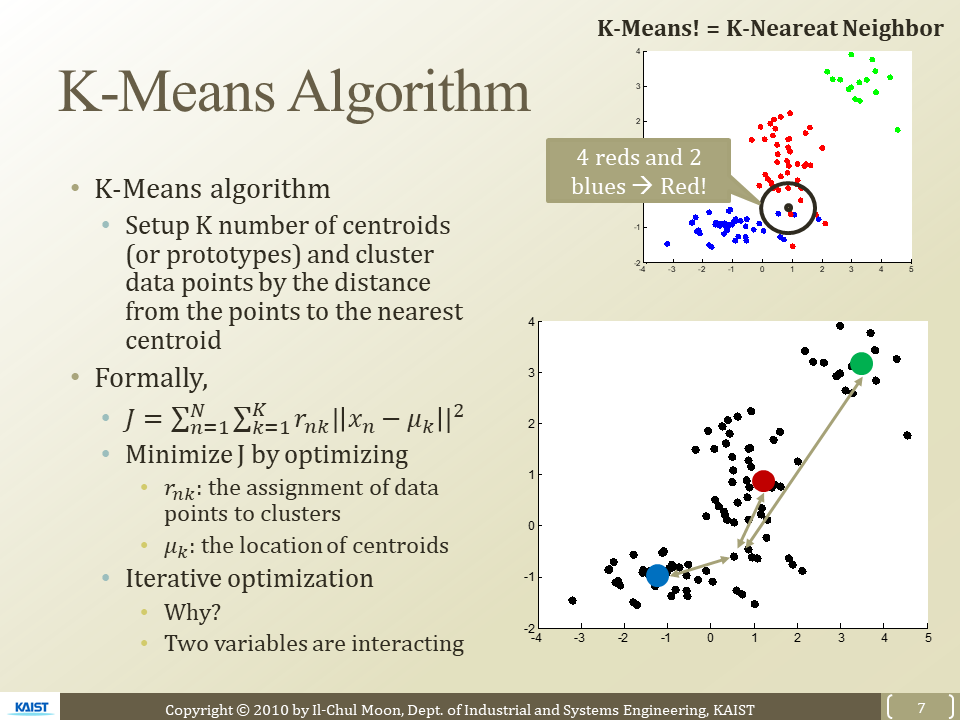
알고리즘 순서
- K개의 Centroid setup
- 각 data points들을 거리가 가까운 Centroid 할당
- Cluster 구성!
목적함수
가장 중요한 것은 각 data points들을 거리가 가까운 Centroid 할당
= 모든 데이터 포인트들이 해당하는 Centroid와의 거리가 최소가 되게 하면 됨!
M : centroid의 위치 , X는 개별 데이터 포인트
R : assignment에 대한 정보
- n번째의 x포인트가 k번째 Centroid에 해당 하면 1 아니면 0
- 계산에 넣을 지 말지 결정 시켜줌!
목적함수의 parameter는 두개(M,S)
이를 Optimize하기 위해서는 iterative Optimization해야함

Expectation - Maximization을 돌아가면서 계속 진행함
- Expectation
- r을 optimize하는 과정
- 초기 centroid들을 임의로 지정 한후 그에 맞게 centroid에 할당하기
- r값이 0,1값 가지지 못해 가지는 문제점
- 애매한 지점에서의 데이터 포인트를 확률이 아닌 0과1로 표현
- Maximization
- M을 optimize하는 과정
- Centroid된 데이터들의 값들의 평균을 내서 M을 optmize
Limitation of K-Means
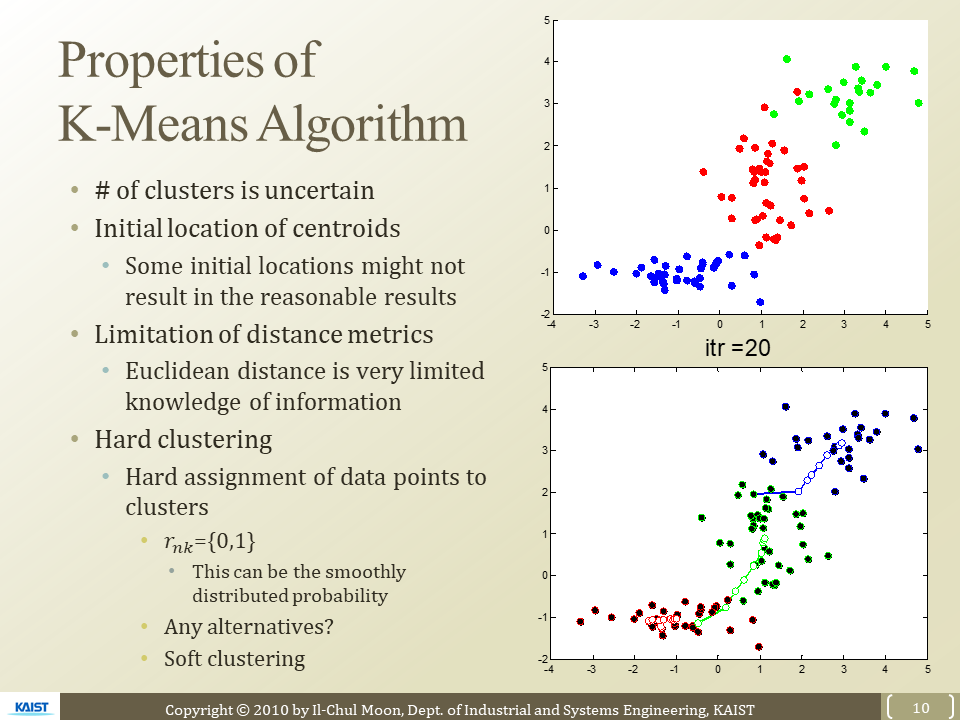
- K의 갯수를 정하는 법?
- Bayesian information criterion 뒤의 강의에서 설명해 주신다고함
- Centroid을 정하는 법
- 초반에 located 임의로 설정하기도 해
- 이도 문제점이 있음 local에 갇힐 수도 있다
- Distance metrics
- 거리로 cluster 형성을 하게되면 위-아래 방향성이나 다른 요소들을 고려 못함
- 원의 형태로의 clustering 밖에 안됨
- 다음 강의Gaussian Mixture Model을 통해 개선
- Hard clustering
- r의 값(데이터 포인트의 할당 값)이 0과 1로만 표현됨
- soft clustering 필요
